Qualitative comparison with optimization-based Gaussian methods
Architecture of Long-LRM
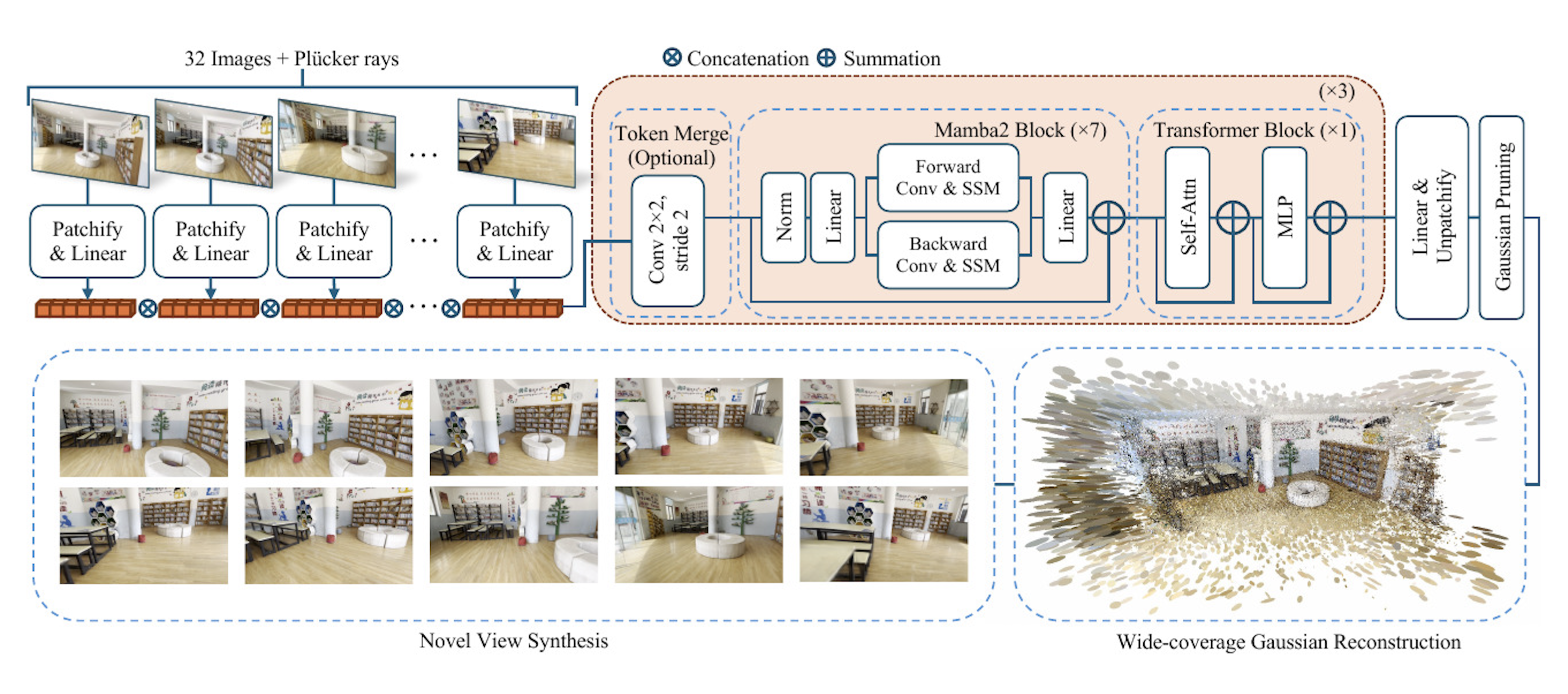 Long-LRM takes 32 input images along with their Plücker ray embeddings as model input, which are then patchified
into a token sequence. These tokens are processed through a series of Mamba2 and transformer blocks ({7M1T}×3).
Fully processed, the tokens are decoded into per-pixel Gaussian parameters, followed by a Gaussian pruning step.
The bottom section illustrates the resulting wide-coverage Gaussian reconstruction and photo-realistic novel view
synthesis.
Long-LRM takes 32 input images along with their Plücker ray embeddings as model input, which are then patchified
into a token sequence. These tokens are processed through a series of Mamba2 and transformer blocks ({7M1T}×3).
Fully processed, the tokens are decoded into per-pixel Gaussian parameters, followed by a Gaussian pruning step.
The bottom section illustrates the resulting wide-coverage Gaussian reconstruction and photo-realistic novel view
synthesis.